

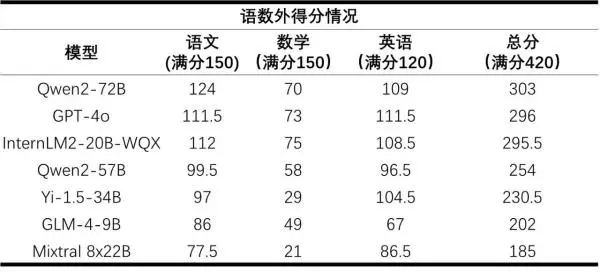
图说:参加高考的6个开源模型和GPT-4o的语数英成绩 来源/上海人工智能实验室(下同)
高考已经告一段落,一群“特殊考生”最先出分!
今年高考甫一结束,上海推出的大模型开源开放评测体系“司南”就选取6个开源模型及GPT-4o进行高考“语数外”全卷能力测试。评测采用全国新课标I卷,参与评测的所有开源模型,开源时间均早于高考,确保评测“闭卷”性。同时,成绩由具有高考评卷经验的教师人工评判,更加接近真实阅卷标准。
结果怎么样呢?“大模型高考”的前三甲得分率均超70%,大部分模型“考生”语文、英语科目表现良好,但在数学方面还有很大的提升空间。
大模型考生比拼新课标I卷
高考,目前已普遍被研究者用于考察大模型的智能水平。
司南评测体系团队选取了GPT-4o及在2024年高考前开源的6个模型,考生分别是——
Mixtral 8x22B:法国AI创业公司Mistral于2024年4月17日开源的对话模型;
Yi-1.5-34B:零一万物公司于2024年5月12日开源的Yi-1.5系列最大的模型;
GLM-4-9B:智谱AI于2024年6月4日推出的最新一代预训练模型GLM-4系列的开源版本;
InternLM2-20B-WQX:上海人工智能实验室于2024年6月4日开源的书生·浦语2.0系列文曲星大语言模型;
Qwen2-57B:阿里巴巴于2024年6月6日开源的Qwen2系列MoE对话模型;
Qwen2-72B:阿里巴巴于2024年6月6日开源的72B稠密模型;
司南评测体系团队称,因无法确定闭源模型的更新时间,为公平起见,此次评测没有纳入商用闭源模型,仅引入GPT-4o作为评测参考。
司南评测体系首次采用高考全卷测试的形式,选取新课标I卷“语数外”三科题目作为测试集。因受测的开源模型均为大语言模型,在评测过程中,仅输入文字题干(数学包含2道带图试题),英语听力部分(分值30分)不纳入此次评测。
首个大模型高考全卷评测结果显示,Qwen2-72B、GPT-4o及书生·浦语2.0文曲星(InternLM2-20B-WQX)成为此次“大模型高考”的前三名,在总分420分的语数英三科较量中,三位“考生”的总分分别是303分、296分和295.5分。
语言能力“不错” 数学“一般”
司南评测体系团队介绍,大部分模型在“语言”本质上的表现良好,语文平均得分率为67%,英语更是达到了81%。
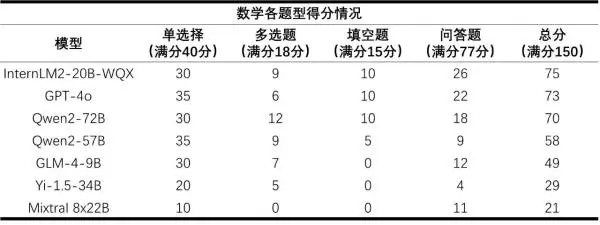
数学则是所有大模型的短板,平均得分率仅为36%。得益于研究团队在数学推理上的投入,InternLM2-20B-WQX取得了75分,在所有受测模型中排名第一——但仍未达到及格水平,这表明大模型的数学能力存在较大提升空间。
参与评测的所有开源模型,权重均在2024年6月7日高考题目公布前开源,避免了“数据污染”和“刷题”风险,与真实高考严格的“闭卷考试”一致,不存在“作弊”可能。
与以往多采用高考客观题考察模型的方式不同,本次测试研究团队使用了语数外三科的全卷试题,既包含选择、填空等“答案唯一性”题目,也包括简答、阅读理解及作文等主观题,在更加接近真实高考的环境中测试模型能力。
为贴近高考评卷模式,联合团队邀请多位具有阅卷经验的高中教师对模型主观题答案评分,每份考卷至少由3位教师分别打分。对于统一回答但教师评分悬殊的情况,则会再次进行复核,尽量避免“争议判卷”的出现。
联合团队认为,如同高考阅卷也存在细微差异,由于主观题类型的引入,本次评测也无法做到绝对的公平。但同时由于主观题的存在,本次测评能够在真实环境中从人的视角考察大模型能力,为学术界和产业界提供更有价值的指标参考。
阅卷前不知道“考生”身份
本次阅卷采用与高考一致的完全匿名形式,所有大模型答卷均进行了匿名处理,避免阅卷教师产生“先入为主”的观念。在阅卷开始前,阅卷教师未被告知答卷均由模型生成,使阅卷教师完全以面对真实考生的标准评判回答效果。
在完成所有大模型答卷的评卷工作后,阅卷教师被告知所评“考生”的真实身份为大模型。研究人员同时邀请各科教师对大模型表现进行了整体分析,为模型能力提升策略提供参考。
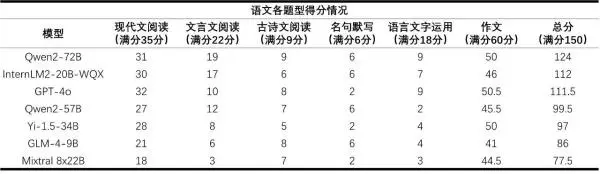
“语文阅卷组”认为:模型的现代文阅读理解能力普遍较强,但是不同模型的文言文阅读理解能力差距较大。大模型作文更像问答题,虽然有针对性但缺乏修饰,几乎不存在人类考生都会使用举例论证、引用论证、名人名言和人物素材等手法。
“数学阅卷组”指出:大模型的主观题回答相对凌乱,且过程具有迷惑性,甚至出现过程错误但得到正确答案的情况。大模型的公式记忆能力较强,但是无法在解题过程中灵活运用。
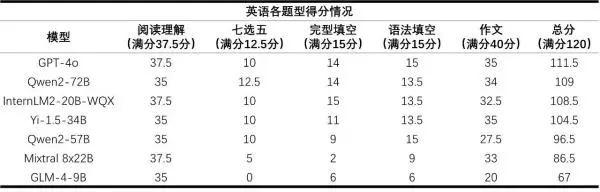
“英语阅卷组”表示:整体表现良好,但部分模型由于不适应题型,在七选五、完形填空等题型得分率较低。大模型英语作文普遍存在因超出字数限制而扣分的情况,而人类考生多因为字数不够扣分。
司南评测体系团队告诉记者,后续将在评测中引入多模态大模型,以考察模型应对更多题型的能力,并陆续发布覆盖不同学科和地区的完整高考评测。